

Conclusion

Dr. Zach Solan
Ai Advisor
I recently received a new paper titled“Evaluation of Sentiment Analysis in Finance: From Lexicons to Transformers” published on July 16 2020 in IEEE. The authors, KostadinMishev, Ana Gjorgjevikj, Irena Vodenska, Lubomir T. Chitkushev, and DimitarTrajanov compared more than a hundred sentiment algorithms that were applied on two known financial sentiment datasets and evaluated their effectiveness. Although the purpose of the study was to test the effectiveness of different Natural Language Processing (NLP) models, the findings, in the paper, can tell us much more, about the progress of NLP over the duration of the last decade, especially, to better understand what elements contributed the most to the sentiment prediction task.
So let’s start with the definition of the sentiment prediction task. Given a collection of paragraphs, the model classifies each paragraph into one of three possible categories: positive sentiment, negative sentiment, or neutral. The model is then evaluated based on a confusion matrix (3X3) that is constructed from the counts of predicted sentiment versus the ground truths (the true labels of each paragraphs).
The evaluation metric implemented by the authors is called the Matthews correlation coefficient (MCC) and serves as a measure of the quality of binary (two-class) classifications (Matthews,1975). Although the MCC metric is only applicable for the binary case, the authors do not mention how they applied the MCC function in the multi-class case (3 sentiment classes). Did they use micro-averaging or did they apply the generalized equation for the multi-class case?
The authors divided the NLP models into five broad categories based on their textual representation: (1) Lexicon-based knowledge, (2) statistical methods, (3) word encoder, (4) Sentence encoder, (5) transformer. Several different models were applied for each category and the performance is reported in a table here.
The table above demonstrates the progress in sentiment analysis through the years driven by the text representation method. The authors confirm that transformers show superior performances compared to the other evaluated approaches and that the text representation plays the main role as it feeds the semantic meaning of the words and sentences into the models.
But wait! There are perhaps more conclusions that can be drawn from this experiment regarding the future of NLP. Can we uncover clues about the elements that are still missing to make NLP much more effective in more complex task? What might be the next big breakthrough in order to better represent human language by language models?
In an effort solve that exact question, I have started to dig further into the models’ outcomes and search for a connection between text representation, model size, and model performance in an attempt to extracting the contribution of model’s size and text representation on the final performance. Based on the authors’ analysis I created the figure below. The Figure below shows the MCC score of each model as a function of the model’s numeric parameters. The colors represent the model main category.
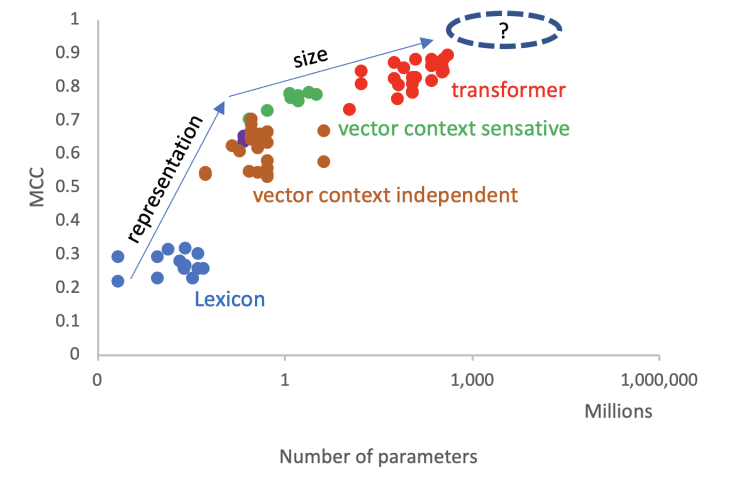
Figure 1: The improvement in sentiment classification (MCC score) as a function of the number of parameters in the models (logarithmic scale)
From my analysis, it can be seen that the progress of the sentiment prediction task consists of two phases. The first phase is mainly attributed to better text representation while the second phase is due to the introduction of the transformer that can handle huge corpora by increasing network size and administrating millions of parameters.
It is highlight from the above graph that text representation had three major revolutions starting from the early 80s. The first was from lexicon representation to embedding vector representation. The main advantage of embedding vectors is its unsupervised nature, as it does not require any tagging while still capturing meaningful semantic relations between words and benefitting from a model’s generalization capabilities. It’s important to remember that these embedding models, such as word2vec and GloVe, are context-independent. They assign the same pertained vector to the same word regardless of the context around the word. Thus, they cannot handle polysemy or complex semantics in natural languages.
Then, the context-sensitive word representations introduced towards 2016 with models like ELMo and GPT. These models have vector representations with words that depend on their contexts. ELMo encodes context bidirectionally, while GPT encodes context from left to right. The main contribution of these was their ability to handle polysemy and more complex semantics.
The most recent revolution in NLP is BERT (Bidirectional Encoder Representations from Transformers), which combines bidirectional context encoding and requires minimal architecture changes for a wide range of natural language-processing tasks. The embeddings of the BERT input sequence is the sum of the token embeddings, segment embeddings, and positional embeddings. BERT and the following models are unique in that they can process a batch of sequences, from 1M parameters to the latest models that reached above 500M. From the graph it can be seen that the number of parameters in the model is the main reason for the continuous performance improvement during the last 4 years.
Although NLP models have come a long way in the recent years and made substantial progress, there is still plenty of room for improvement. According to several studies,1,2 just increasing the network size is not enough, and even today the model is in a state of overparametrization. The next breakthrough will probably come from further progress in text representation, when NLP models will be better able to capture language compositionality (the ability to learn the meaning of a larger piece of text by composing the meaning of its constituents maintaining). A good place to start looking for some ideas about new text representations is in the domain of grammar inference. By learning controlled formal grammar, we can go deeper into our understanding about the elements that should handle compositionally (Solan et al, 2005) with respect to tests, like systematically, substitutivity, productivity, localism etc. (Hupkes et al., 2019; Onnis & Edelman, 2019).
Biography
(1) Hupkes, D., Dankers, V., Mul, M., & Bruni, E. (2019). The compositionality of neural networks: integrating symbolism and connectionism. arXiv preprint arXiv:1908.08351.
(2) Kovaleva, O., Romanov, A., Rogers, A., &Rumshisky, A. (2019). Revealing the dark secrets of BERT. arXiv preprint arXiv:1908.08593.
(3) Onnis, L., & Edelman, S. (2019). Local versus global statistical learning in language.
(4) Solan, Z., Horn, D., Ruppin, E., & Edelman, S. (2005). Unsupervised learning of natural languages. Proceedings of the National Academy of Sciences, 102(33), 11629–11634.
(5) Mishev, K., Gjorgjevikj, A., Vodenska, I., Chitkushev, L. T., & Trajanov, D. (2020). Evaluation of Sentiment Analysis in Finance: From Lexicons to Transformers. IEEE Access, 8, 131662–131682.


